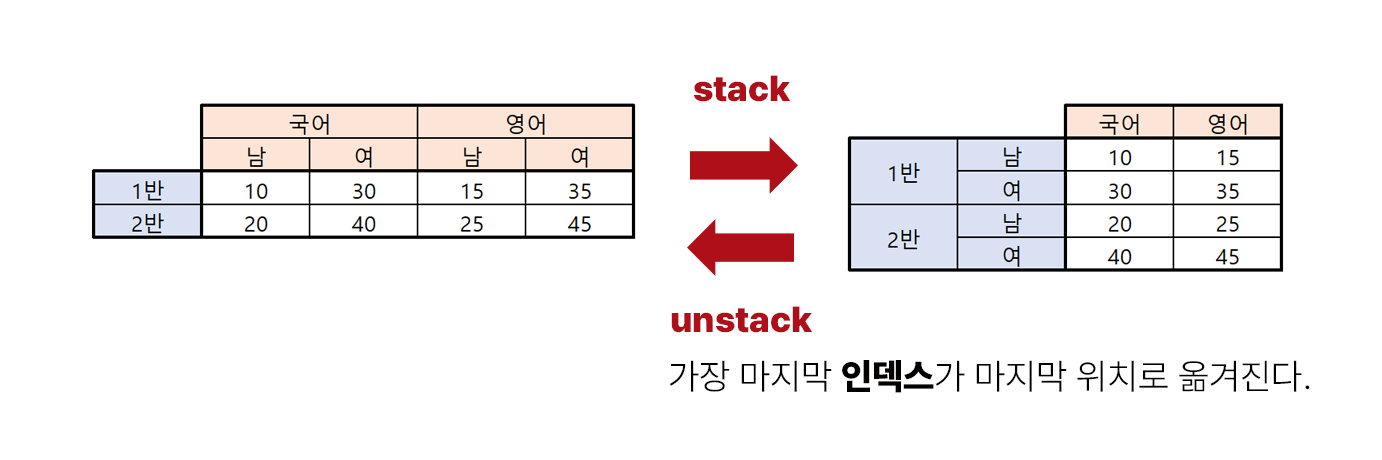
인덱스나 컬럼즈의 데이터를 상호 이동해 데이터의 구조를 변경하는 함수
stack은 columns를 index로 이동시키고 unstack은 index를 columns로 이동시킨다
import pandas as pd
data = [[10, 20, 30, 40], [15, 25, 35, 45]]
col1 = pd.MultiIndex.from_product([['남', '여'], ['A반', 'B반']])
df = pd.DataFrame(data, index=['1학년', '2학년'], columns=col1)
stack 함수의 주요 매개변수(parameter)와 인수(argument), 기본값(default)
df.stack(level=-1, dropna=True)
level (level의 레이블 혹은 로케이션, 또는 그것들의 리스트 / 기본값은 -1)
index로 이동할 columns의 level을 지정하는 매개변수. 기본값은 -1이라서 맨 마지막 columns를 보낸다
dropna (인수는 bool / 기본값은 True)
stack 함수를 적용한 후에 값이 NaN인 행이 생성될 수 있는데 값이 NaN인 행은 생성할지 삭제할지 결정하는 매개변수.
unstack 함수의 주요 매개변수(parameter)와 인수(argument), 기본값(default)
df.unstack(level=-1, fill_value=None)
level (level의 레이블 혹은 로케이션, 또는 그것들의 리스트 / 기본값은 -1)
columns로 이동할 index의 level을 지정하는 매개변수. 기본값은 -1이라서 맨 마지막 index를 보낸다
fill_value
NaN을 대체할 값을 지정하는 매개변
공식 문서 링크
https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.stack.html
pandas.DataFrame.stack — pandas 1.5.3 documentation
Level(s) to stack from the column axis onto the index axis, defined as one index or label, or a list of indices or labels.
pandas.pydata.org
https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.unstack.html
pandas.DataFrame.unstack — pandas 1.5.3 documentation
previous pandas.DataFrame.tz_localize
pandas.pydata.org
'판다스 > 함수 cheat sheet' 카테고리의 다른 글
| [pandas] fillna (0) | 2023.02.24 |
|---|---|
| [pandas] melt (0) | 2023.02.20 |
| [pandas] reindex (0) | 2023.02.19 |
| [pandas] set_axis (0) | 2023.02.19 |
| [pandas] reset_index (0) | 2023.02.19 |



