넘파이의 np.fmax와 np.fmin 함수를 이용해 배열 비교
넘파이의 np.fmax와 np.fmin 함수는 두 배열을 비교하여 각 위치에서 더 큰 값이나 더 작은 값을 반환하는 유용한 함수입니다. 물론 불리언 마스킹으로도 구현할 수 있지만, 불리언 마스킹에 비해 더 간결한 코드로 수행할 수 있습니다. 이해를 돕기 위해 간단한 예시를 살펴보겠습니다.
예시
import pandas as pd
# 예시 데이터 프레임 생성
data = {'반': ['A', 'B', 'B', 'A', 'A'],
'국어': [81, 96, 83, 66, 84],
'영어': [54, 42, 31, 68, 69]}
df = pd.DataFrame(data)
예시 데이터 프레임 df에서 영어 점수에 30점을 가산한 후, 국어 점수와 비교하여 더 높은 점수를 반환해 보겠습니다. 이 작업은 불리언 마스킹으로도 가능하지만, np.fmax를 사용하면 훨씬 더 간결하게 수행할 수 있습니다. np.fmax 함수는 두 개의 배열을 비교하여 각 위치에서 더 큰 값을 반환합니다.
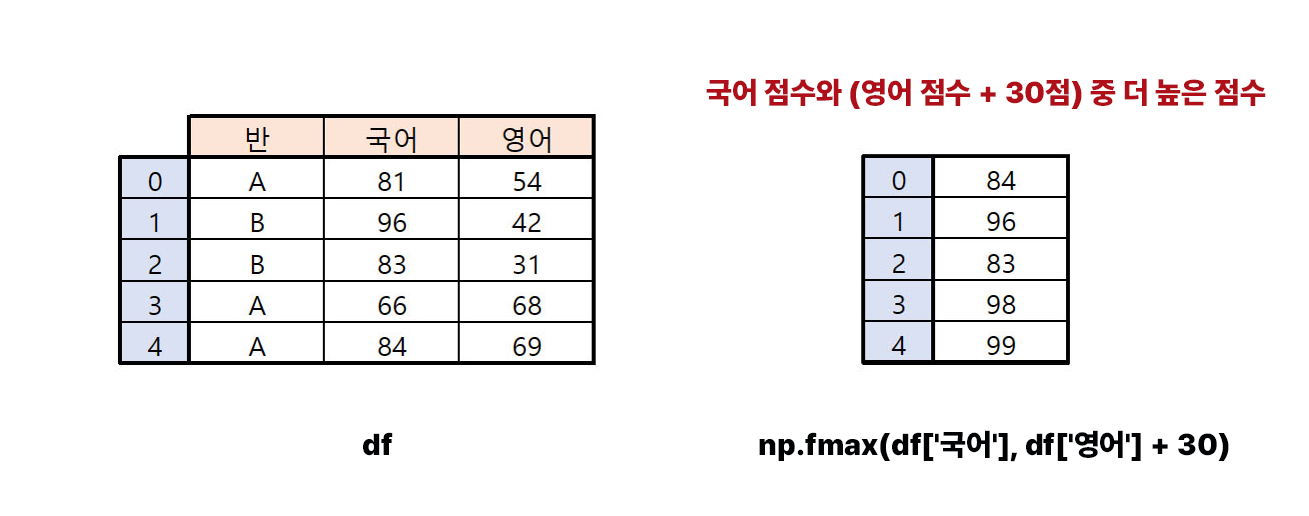
# 영어에 가산점 30을 주고 국어 점수와 비교해 높은 점수 반환
np.fmax(df['국어'], df['영어'] + 30)위 코드는 간편하게 국어 점수와 영어 점수에 30점을 더한 값 중 큰 값을 반환합니다. 데이터 프레임 내에서 열 간의 비교를 수행할 때는 집계 함수를 사용할 수도 있지만, 하나의 데이터 프레임에 속하지 않는 배열 간의 비교가 필요한 경우 np.fmax를 사용하는 것이 더욱 간편합니다.
np.fmin 함수는 np.fmax와 반대로, 두 개의 배열을 비교하여 각 위치에서 더 작은 값을 반환합니다. 예를 들어, 국어 점수와 영어 점수에 가산점 30점을 더한 값 중 더 낮은 값을 선택하려면 다음과 같이 코드를 작성할 수 있습니다.
# 영어에 가산점 30을 주고 국어 점수와 비교해 낮은 점수 반환
np.fmin(df['국어'], df['영어'] + 30)

유튜브에서 판다스 강의 중입니다.
https://www.youtube.com/@KimPandas
'판다스 > 판다스에 유용한 넘파이 함수들' 카테고리의 다른 글
| [numpy] np.sort 함수로 행이나 열의 개별적 정렬 (4) | 2024.10.26 |
|---|---|
| [numpy] np.select 함수로 불리언 마스킹 (3) | 2024.10.26 |
| [numpy] np.where 함수로 불리언 마스킹 (3) | 2024.10.26 |
| [numpy] 난수 생성 함수 (3) | 2024.10.26 |



