
교보문고 구매 페이지, 알라딘 구매 페이지, yes24 구매 페이지
CHAPTER 01과 CHAPTER 02의 내용은 아래 링크로 확인하실 수 있습니다.
파이썬의 엑셀, 판다스 라이브러리
CHAPTER 01 판다스 입문
1.1 판다스 소개
1.2 파이썬 개발 환경
CHAPTER 02 파이썬 기초와 넘파이 라이브러리
2.1 변수와 자료형
2.2 제어문과 함수
2.3 클래스와 객체, 라이브러리
본 포스팅의 내용은 책에서 발췌된 자료로, 저작권 보호를 받고 있습니다.
허락 없이 복제나 배포는 삼가해 주시기 바랍니다.
1.1 판다스 소개
우리는 데이터의 세상에 살고 있다. 하루에도 엄청난 양의 데이터가 생성되며 이 데이터 속에는 가치있는 정보와 지식이 숨겨져 있다. 데이터는 숫자나 문자의 단순한 나열이 아니다. 이는 새로운 발견을 가능하게 하고, 비즈니스의 성장을 이끌며, 사회적 문제에 대한 해결책을 제시한다.
현대 사회에서 데이터를 다루는 능력은 선택이 아닌 필수이다. 많은 직장인은 업무의 대부분을 데이터를 다루는 데 투자한다. 데이터 분석, 데이터 기반의 의사 결정 그리고 데이터를 통한 새로운 비즈니스 모델의 창출은 직장인들의 주요 업무 중 하나이다. 이는 데이터를 다루는 기술이 개인의 경쟁력을 크게 좌우한다는 사실을 의미한다.
파이썬의 판다스 라이브러리는 데이터 처리 기술을 몇 단계 도약시키는 강력한 도구이다. 판다스는 사용자가 방대한 데이터를 효율적으로 조작하고 분석하도록 돕는다. 이전에는 불가능하던 데이터 처리 작업을 수행하게 해주고 기존 작업도 몇 배나 빠르게 수행하게 한다.
이 책은 판다스의 기본에서 시작하여 심화 기법까지 단계별로 안내한다. 독자는 이 책을 통해 데이터 분석의 기초를 다지고 실제 업무에 적용하는 고급 기술을 습득할 것이다. 데이터 분석의 세계로 첫 발걸음을 떼려는 이들과 데이터 처리 기술을 향상하려는 이들에게 이 책은 좋은 길잡이가 될 것이다.
1.1.1 판다스 라이브러리란?
데이터 분석 분야에서 파이썬은 풍부한 라이브러리(library) 덕분에 특히 높은 인기를 자랑한다. 라이브러리는 특정 작업을 수행하는 데 필요한 코드와 기능들의 모음이다. 이는 새로운 작업을 수행할 때마다 동일한 코드를 반복해서 작성하는 대신 필요한 기능을 라이브러리를 통해 쉽게 재사용하도록 해준다. 쉽게 말해 라이브러리는 누군가가 이미 만들어둔 함수 모음이며, 라이브러리를 활용해 해당 함수들을 사용한다.
판다스(Pandas)는 데이터 분석 분야에서 필수적인 라이브러리로 자리매김하고 있다. 판다스는 데이터를 효율적으로 처리하고 분석하는 다양한 기능을 제공한다. 특히 데이터 프레임(data frame)이라는 클래스를 통해 표 데이터를 쉽게 조작하고 분석하게 해준다. 이는 엑셀 등 스프레드시트 프로그램에서 작업하는 것과 유사하지만, 데이터를 훨씬 더 강력하고 유연하게 처리한다. 실제로 엑셀 파일과 CSV 파일의 데이터도 손쉽게 데이터 프레임으로 불러와 강력한 판다스 함수로 데이터를 처리한다.
요약하면 판다스는 표 데이터 처리에 특화된 라이브러리로서 엑셀 및 csv 파일의 데이터를 손쉽게 데이터 프레임으로 다룬다. 또한 여러분에게 표 데이터를 효율적으로 다루게 해주는 많은 함수를 제공하는 라이브러리이다.
1.1.2 마이크로소프트의 엑셀에 탑재된 판다스
마이크로소프트가 자사의 엑셀에 파이썬을 탑재했다. 이를 통해 엑셀의 사용성과 기능성이 대폭 향상되고 데이터 분석가들은 많은 변화를 경험할 것이다. 엑셀은 표 데이터를 스프레드시트 형태로 처리한다. 따라서 엑셀에서 파이썬을 탑재했다는 것은 표 데이터를 처리하는 데 파이썬을 활용하겠다는 것이고, 그것은 파이썬에서 표 데이터 처리에 특화된 판다스를 엑셀에서 사용하겠다는 의미이다. 실제로 엑셀에 탑재된 파이썬에서는 판다스를 별도의 설치 없이 사용하도록 설정되어 있다. 이제 엑셀 사용자들은 판다스의 강력한 데이터 분석 기능을 엑셀 환경에서 직접 활용할 수 있게 되었다.
이는 표 데이터 처리를 위한 판다스의 탁월한 활용성을 마이크로소프트도 인정했고, 여러분이 판다스를 배워두면 추후 엑셀에서도 활용이 가능하다는 의미이다.
1.1.3 판다스의 장점
그렇다면 어떤 장점 때문에 마이크로소프트가 판다스를 엑셀에 탑재한 것일까? 판다스의 장점은 다음처럼 요약할 수 있다.
첫째, 판다스는 대용량 데이터의 처리 속도가 매우 빠르다. 이를 통해 사용자는 방대한 양의 데이터를 효율적으로 관리하고 분석하며, 데이터 전처리 및 분석 작업을 신속하게 수행한다. 실제로 100만 행의 데이터도 효율적인 코드로 처리하면 0.1초 이내의 실행 시간이 소요된다.
둘째, 판다스의 코드 작성이 직관적이다. 판다스의 함수는 명료하고 직관적인 방식으로 설계되어 사용자가 데이터를 쉽게 이해하고 작업하게 해준다.
셋째, 인덱스를 활용한 데이터의 갱신 및 관리가 탁월하다. 판다스는 인덱스를 사용하여 데이터를 명확하게 구분하고, 이를 기반으로 데이터를 쉽게 업데이트하거나 수정하도록 지원한다.
넷째, 열과의 상호 작용이 용이하다. 판다스는 열 기반의 데이터 조작이 쉽도록 설계되어 특정 열에 대한 연산이나 데이터 처리 작업을 간편하게 수행한다. 이뿐만 아니라 특정 열의 데이터로 그룹화하여 데이터를 처리하는 그룹화 연산에도 큰 강점이 있다.
다섯째, 벡터화 연산을 지원한다. 벡터화 연산을 통해 여러 데이터에 대한 연산을 한 번에 수행하여, 코드의 실행 속도를 향상하고 효율성을 높인다.
마지막으로, 판다스는 시계열 데이터를 다루는 데 특히 뛰어나다. 본래 판다스는 금융 데이터를 손쉽게 다루고자 탄생한 라이브러리이다. 그리고 금융 데이터는 시간에 따른 데이터 분석이 필요하므로 판다스는 본래 용도에 맞게 강력한 시계열 데이터 처리 기능을 제공한다.
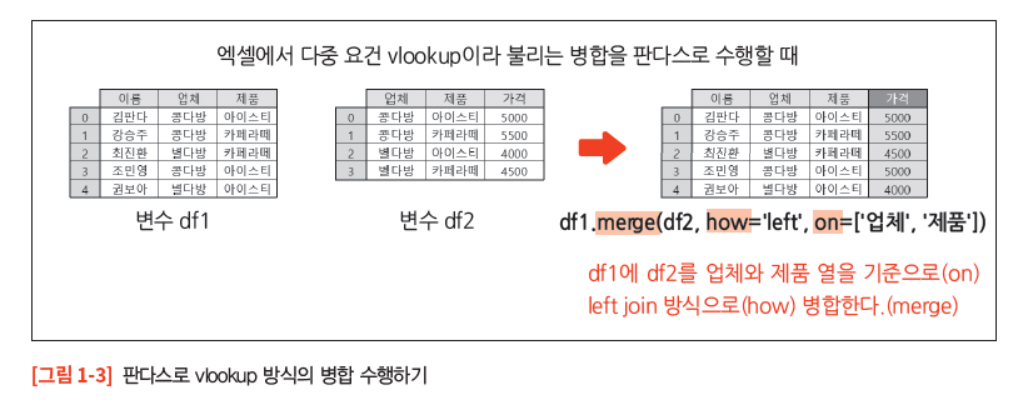
예시를 통해 판다스의 장점을 살짝 경험해 보자. [그림 1-3]의 첫 번째 표는 각 사람이 선택한 음료를 나타내는 데이터이며 변수 df1로 지정되었다. 두 번째 표는 각 메뉴의 가격을 나타내는 데이터이며 변수 df2로 지정되었다. 그런데 df2의 가격 정보를 df1에 병합하고 싶다면 어떻게 해야 할까? 엑셀에서는 이러한 병합을 vlookup 함수로 수행한다. 특히 이때는 업체와 제품이라는 두 개의 열을 기준으로 vlookup을 수행해야 하기 때문에 ‘다중 요건 vlookup’이라고 한다.
판다스는 열과의 상호 작용이 뛰어나다. 그래서 이런 다중 요건 vlookup도 기준 열을 복수로 지정하는 것만으로 간편하게 수행할 수 있다. 또한 판다스의 코드는 인간의 언어와 흡사할 정도로 직관적이다.
# df2 merge to df1 by left join based on '업체', '제품'
df1.merge(df2, how='left', on=['업체', '제품'])
그리고 예시의 코드는 규모가 크지 않은 데이터이지만 이 데이터가 100만 행에 이르더라도 0.1초 수준의 시간에 코드가 실행될 정도로 빠른 처리 능력을 자랑한다. 여담으로 파이썬이 엑셀에 탑재되어, 이러한 다중 요건 vlookup을 손쉽게 수행하는 것만으로도 판다스는 학습 가치가 충분하다.
'파이썬의 엑셀, 판다스 라이브러리 > CHAPTER 01. 판다스 입문' 카테고리의 다른 글
| 1.2 파이썬 개발 환경 (0) | 2024.10.15 |
|---|
