예제 :
# 예제 생성
import pandas as pd
data1 = {('김판다', '영어'): [50, 20, 35],
('김판다', '국어'): [60, 5, 45],
('강승주', '영어'): [70, 10, 60],
('강승주', '국어'): [100, 30, 50]}
df = pd.DataFrame(data1)
df:

문제 : 멀티 인덱스인 열을 가지고 있을 때 subtotal 열 만들어 봅시다.

groupby의 axis=1이 판다스 2.1.0+에서 사라지기 때문에 전치 데이터 프레임 T를 활용해야 합니다.

subtotal 행을 만드는 사용자 정의 함수를 생성해 그룹바이 객체에 apply 함수와 함께 적용합니다.
이때 group_keys=False는 필수입니다
# subtotal 행을 생성하는 사용자 정의 함수
def get_subtotal(df):
df.loc[(df.index[0][0], '총점'), :] = df.sum()
return df
# groupby로 사용자 정의 함수 적용
out = (df.T.groupby(level=0, group_keys=False, sort=False)
.apply(get_subtotal).T
)
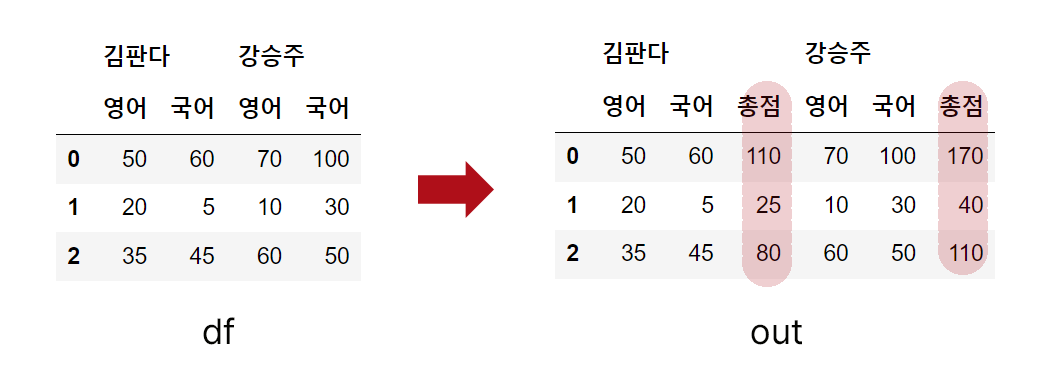
사실 이것을 수행하는 방법은 여러가지가 있는데
정렬상태를 그대로 유지하고 싶다면, groupby가 가장 편리합니다.
'판다스 > 판다스 팁' 카테고리의 다른 글
| [pandas] 멀티 인덱스의 각 레벨의 유일 값 찾기 (0) | 2024.02.20 |
|---|---|
| [pandas] 멀티 인덱스에서 두 번째 레벨의 값으로 인덱싱하는 방법 (0) | 2024.02.20 |
| [pandas] plot 함수로 subplot 그리는 방법 (0) | 2024.02.16 |
| matplotlib의 컬러맵에서 색상을 지정해 그래프를 그리는 방법 (0) | 2024.02.13 |
| pandas 에서 plotly 기반으로 그래프를 그리는 방법 (0) | 2023.12.22 |



