시간의 흐름에 따라 그룹화해서 함수를 적용하는 함수
import pandas as pd
data = {'날짜': ['2023-01-01', '2023-01-15', '2023-01-30',
'2023-01-31', '2023-02-02', '2023-02-05'],
'금액': [10000, 20000, 30000, 40000, 50000, 60000]}
df = pd.DataFrame(data)
df['날짜'] = pd.to_datetime(df['날짜'])
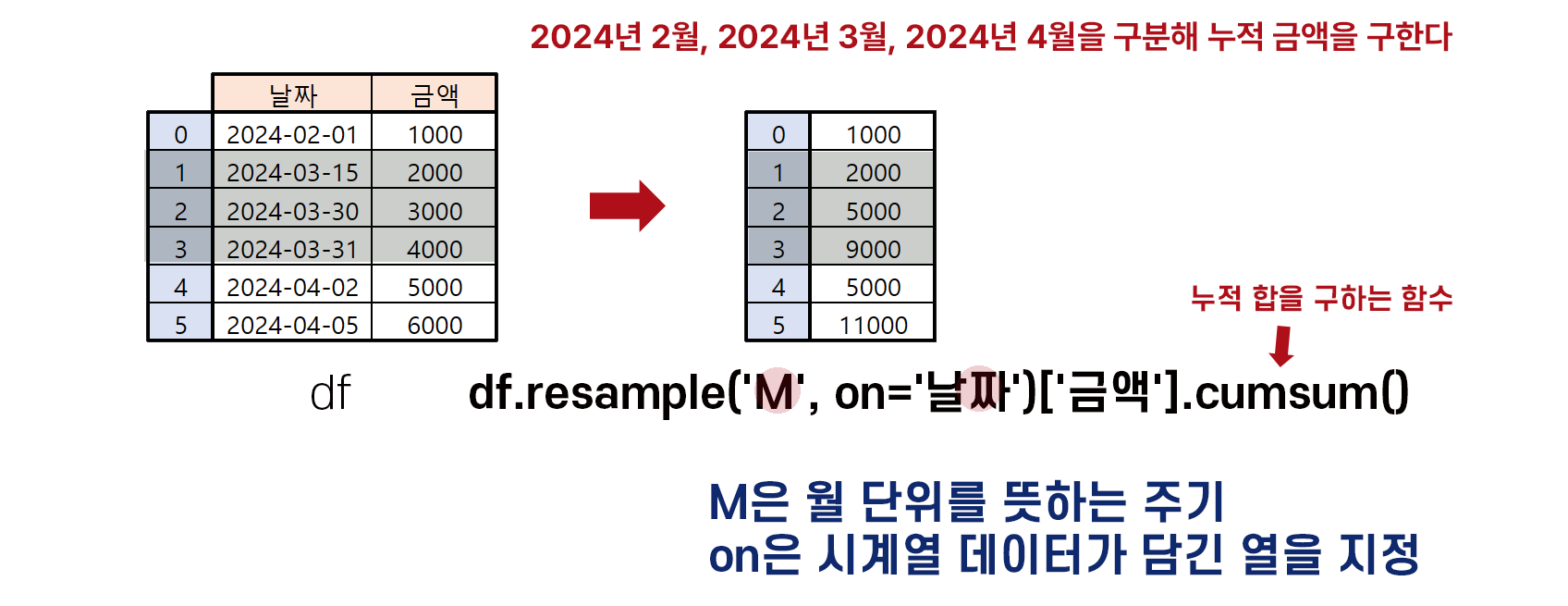
df.resample('M', on='날짜')['금액'].cumsum()
resample 함수의 주요 매개변수(parameter)와 인수(argument), 기본값(default)
df.resample(rule, on=None, level=None, origin='start_day')
rule
집계할 주기를 입력 (예: 일단위 집계라면 'D', 월단위 집계라면 'M' 또는 'MS')
on
시계열 데이터가 담긴 열을 지정하는 매개변수. 반드시 datetime 자료형이어야 한다
시계열 데이터가 index라면 지정할 필요가 없다
level
멀티인덱스일때 시계열 데이터가 존재하는 index의 level을 지정하는 매개변수.
origin
기간의 기준 시작점을 수정하고 싶을 때 지정하는 매개변수.
- 'epoch': 1970-01-01
- 'start': 시계열 데이터의 첫 번째 값
- 'start_day': 시계열 데이터의 첫 번째 날짜의 00:00:00
유튜브에서 판다스 강의 중입니다
https://www.youtube.com/@KimPandas
'판다스 > 함수 cheat sheet' 카테고리의 다른 글
| [pandas] select_dtypes (0) | 2023.12.20 |
|---|---|
| [pandas] between (2) | 2023.11.25 |
| [pandas] cumcount (0) | 2023.08.17 |
| [pandas] crosstab (0) | 2023.07.30 |
| [pandas] clip (0) | 2023.07.16 |



