다음과 같은 시리즈 s가 있다
import pandas as pd
s = pd.Series(['AAAAA-BB-CCCCCC-DD-EEE', 'CCCCCC-AA-BBB-DD-EEE'])
s
0 AAAAA-BB-CCCCCC-DD-EEE
1 CCCCCC-AA-BBB-DD-EEE
dtype: object
s에서 A-와 그 다음에 존재하는 첫번째 - 사이의 문자열만 추출해보자
첫째 행에서는 BB를 추출하고 두번재 행에서는 BBB를 추출해야 한다
정규 표현식을 이용해 다음과 같이 추출할 수 있다
s.str.extract(r'A-(.*?)-')
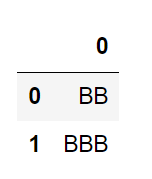
이 때 정규표현식으로 그룹명을 지정하면 column의 이름이 바뀐다
그룹명을 keyword로 작성해보자
s.str.extract(r'A-(?P<keyword>.*?)-')

열 이름이 keyword로 바뀌었다.
물론 판다스 함수로 rename이나 set_axis등으로 열이름을 바꿔주는 것도 가능하다.
유튜브에서 판다스 강의 중입니다
'판다스 > 판다스 팁' 카테고리의 다른 글
| [pandas] set과 frozenset의 차이 (0) | 2023.08.07 |
|---|---|
| [pandas] 특정 열의 값으로 데이터 프레임 나눠서 리스트로 만들기 (0) | 2023.08.06 |
| [pandas] 일부만 %로 표기된 열을 float으로 바꿀 때 (0) | 2023.07.05 |
| [pandas] 파일에서 데이터 프레임을 읽어올 때 공통된 열이름이 있을 때 해결책 (0) | 2023.06.25 |
| [pandas] 문자열을 csv파일처럼 읽어 데이터 프레임으로 부르고 싶을 때 (0) | 2023.06.25 |

