판다스의 데이터 프레임에서 큰 숫자의 가독성을 개선하는 방법
데이터 분석을 하다 보면 대규모 데이터셋에서 큰 숫자를 다루게 되는 경우가 많습니다. 특히, 숫자가 크면 클수록 값을 직관적으로 이해하기 어려워지기에, 가독성을 높이는 것이 중요합니다. 이번 글에서는 데이터 프레임에서 큰 숫자를 좀 더 가독성 좋게 표기하는 방법을 알아보고자 합니다.
Example Code
import pandas as pd
data = {'일련번호':[2101, 2102, 2103],
'금액':[123000000, 456000000, 1230000000]}
df = pd.DataFrame(data)
df

Problem
예시 데이터 프레임은 금액 열에 큰 숫자가 포함되어 있어 가독성이 떨어집니다.
이를 개선하기 위해 금액 열의 숫자 형식을 변경하여 더 쉽게 읽을 수 있도록 표현하겠습니다.
해결책 1: 수치형 데이터를 문자열로 변환하기
파이썬에서는 숫자를 세 자리마다 콤마가 삽입된 문자열로 변환할 수 있습니다.
# 숫자를 세 자리마다 콤마가 적용된 문자열로 변환하는 파이썬 기법
a = 123000000
'{:,}'.format(a)'123,000,000'
판다스의 apply 또는 map 함수를 사용하면 시리즈의 각 셀에 파이썬 함수나 기법을 적용할 수 있습니다. 이를 통해 금액 열의 숫자를 세 자리마다 콤마가 적용된 문자열로 변환할 수 있습니다.
# 시리즈의 각 셀에서 숫자를 세 자리마다 콤마가 적용된 문자열로 변환
df['금액'].apply('{:,}'.format)0 123,000,000
1 456,000,000
2 1,230,000,000
Name: 금액, dtype: object
위의 결과로 금액 열을 수정하면 세 자리마다 콤마가 삽입된 문자열을 얻을 수 있지만, 이 방식은 기존의 수치형 데이터가 문자열로 변환되는 단점이 있습니다. 이를 피하려면 열을 수정할 때 assign 함수를 사용하여 원본 수치 데이터는 원본(df)에서 유지되도록 하는 것이 좋습니다.
# assign 함수로 열 수정하기 (df를 덮어쓰지 않음)
df.assign(금액=df['금액'].apply('{:,}'.format))
해결책 2: 데이터의 형식은 유지하고 표시만 변경하기
데이터 자체는 수치형으로 그대로 유지하면서 표시 형식만 변경하고자 한다면 style.format 함수를 활용할 수 있습니다.
2-1. 매개변수 thousands를 사용하여 콤마 삽입
매개변수 thousands를 활용하면 세 자리마다 콤마를 부여할 수 있습니다.
# style.format + 매개변수 thousand로 각 자리수에 콤마를 지정
df.style.format(thousands=',')다만, 이 방식은 데이터 프레임 전체에 콤마를 적용하므로, 일련번호 열에도 콤마가 삽입되는 단점이 있습니다.
2-2. 매개변수 formatter를 사용하여 특정 열에만 콤마 삽입
특정 열에만 숫자 형식을 적용하고자 한다면 매개변수 formatter를 사용할 수 있습니다.
# style.format + 매개변수 formatter로 특정 열만 지정한 숫자 표기를 적용
df.style.format(formatter={'금액':'{:,}'.format})
2-3. 과학적 표기법으로 변환하기
꼭 콤마 표기를 사용할 필요는 없습니다. 경우에 따라 과학적 표기법이 더 적합할 수 있습니다. 물론 이 경우에도 금액 열만 변환해야 하므로 매개변수 formatter를 사용해야 합니다.
# 금액 열을 과학적 표기법(예: 1.23 × 10^4)으로 표시
df.style.format(formatter={'금액':'{:.2e}'.format})
2-4. 사용자 정의 포맷 적용하기
특정 단위로 숫자를 표기해야 하는 경우에는 사용자 정의 포맷을 사용할 수 있습니다. 예를 들어, 금액을 억 단위로 표기할 수 있습니다.
# 금액 열을 억 단위(예: 1.23억)로 표시
fmt = lambda x: '{:.2f}억'.format(x/(10**8))
df.style.format(formatter={'금액':fmt})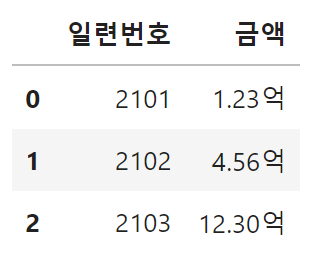
또는 열 이름에 단위를 표시하고, 숫자는 억 단위로 표기할 수도 있습니다. 이 방법은 style.format 함수가 필요하지 않습니다.
# 금액을 1억으로 나누고, 열 이름에 '억' 단위를 추가
df.assign(금액=df['금액'].div(10 ** 8)).rename({'금액': '금액(억)'}, axis=1)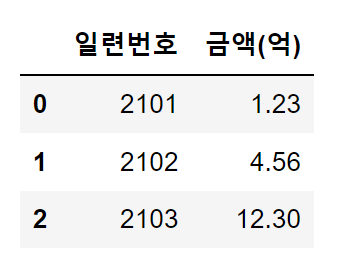
2-5. 값의 크기에 따른 색상 부여하기
값의 크기를 시각적으로 구분하는 것이 목적이라면, 색상을 활용하는 것도 한 가지 방법입니다.
# 금액 열에 Reds 계열의 그라디언트 색상을 배경으로 적용
df.style.background_gradient(cmap='Reds', subset=['금액'])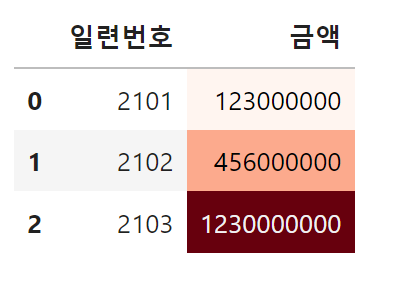
위에서 설명한 여러 방법들을 통해 데이터 프레임에서 큰 숫자의 가독성을 높일 수 있습니다. 상황에 맞는 적절한 방법을 선택하여 데이터를 보다 직관적으로 표현할 수 있습니다.
판다스 책이 출판되었습니다.

유튜브에서 판다스 강의 중입니다.
https://www.youtube.com/@KimPandas
'판다스 > 판다스 팁' 카테고리의 다른 글
| [pandas] read_clipboard 함수쓸 때 데이터에 공백이 있을 때 처리방법 (0) | 2023.06.01 |
|---|---|
| [pandas] 그룹별로 가장 가까운 값을 기준으로 NaN을 채우기 (0) | 2023.05.27 |
| [pandas] 데이터 프레임에서 퍼센트(%)로 수치를 표기하는 방법 (0) | 2023.05.26 |
| [pandas] 주피터 노트북에서 여러개의 데이터 프레임을 가로로 출력하기 (0) | 2023.05.26 |
| [pandas] 구글 코랩과 주피터 노트북 비교 : 파일에서 데이터 프레임을 불러오는 방식의 차이 (0) | 2023.05.25 |



